Deep semantics I
Confusion around understanding
Among researchers and philosophers there seems to be a good deal of confusion around what goes on in our minds when we understand language. Both language and understanding are loaded concepts with a lot of baggage (similarly to e.g. consciousness) and there seems to be little to hang on to when trying to connect them with the representational processes happening in the mind. We might ask the same question about language understanding in transformer networks. What information is the transformer representing about tokens and how is it using this information when producing fluent text? Could we reduce its mode of operation “just” to the modelling of conditional probabilities for a set of tokens when given a sequence of preceding tokens or is there some other seemingly equivalent mechanism behind it? Finally, there is quite a bit of controversy among researchers even about the meaning of the term “understand”. In case you would like to witness a clash of titans around the meaning of “understanding” then I suggest to you check out The Minds I (chapter 22) featuring John Searle, Douglas Hofstadter, Daniel Dennet and other heavy-weights.
Could humans be doing both probabilistic reasoning (e.g. “green grass” sounds right whereas “blue grass” is less so) and deep semantic analysis (e.g. “grasses are plants and most plants are green because they contain chlorophyll that scatters green light. But in the autumn grass becomes brownish because the chlorophyll degrades etc.”)? In that sense, probabilistic and semantic reasoning are often equivalent. For example, an expression to the effect of “boy kicked stone” is more likely to be found in a linguistic corpus than “stone kicked boy”, precisely because “boy” refers to a human being and human beings exhibit agency (e.g. by kicking stuff around), but stones do not do that. Thus, semantically consisent expressions are also more frequent in written and spoken language. As a consequence, sufficiently powerful models are expected to model at least some aspects of interrelations between concepts (e.g. infer parts of speech for common words etc) based on statistical regularities observed in the training data.
Such relationships between concepts are the essential, defining, aspects of meaning and, in fact, possessing the appropriate relationships allows you to determine the reference.
When looking for the mechanisms of understanding, one might propose that symbols such as words are defined by their referents (i.e. the things they refer to in the real world). This is however a bit tricky since we can conjure up entities that do not exist:



I generated these examples with the help of DALL-E to illustrate that we (and dedicated algorithms) can dream up fictional entities (entities with no referents in the real world) that are nevertheless meaningful and representable (they can be imagined, rendered etc). Accordingly, we have to accept that there can be meaning without reference, unless we accept a relaxing pre-condition that the referent can also be another representation. Of course, most of us have a pretty good knowledge about the referents of “blue” and “banana”.
Given that
-
banana is a fruit with a distinct shape
-
it is typically of yellow color
-
blue is also a color
we can mentally swap the color attribute in the banana from yellow to blue and understand what “a blue banana” means.
The fact that we are able to perform such mental symbolic operations is dubbed as the “compositionality of meaning”. The principle of compositionality suggests that we are able to conceptualize discrete (i.e. limited) aspects of the world (e.g. entities, attributes, actions etc.) and combine these concepts in terms of meaningful relations. Meaningful means here more-or-less something that can be consistently represented in the minds of the people who make an effort to interpret a given linguistic expression.
The Principle of Semantic Compositionality (sometimes called ‘Frege’s Principle’) is the principle that the meaning of a (syntactically complex) whole is a function only of the meanings of its (syntactic) parts together with the manner in which these parts were combined.
The hypothesis of semantic compositionality
For quite some time, I have wondered what would happen if we were to follow the principle of semantic compositionality to the letter and devise a symbolic system to emulate it. What would the notation, expressions and functions of this system look like? Furthermore, if we were to use such a system, would it lead to more clarity about the nature of meaning and language understanding? Toying around with these ideas and testing them in code has led me down a rabbit hole with no end in sight. But, besides some difficulties and initial setbacks, the results seem promising (more on that below).
As the guiding star, I have adopted the following excerpt from the “Foundation”:
Said Yate Fulham: “And just how do you arrive at that remarkable conclusion, Mr. Mayor?”
“/…/ You see, there is a branch of human knowledge known as symbolic logic, which can be used to prune away all sorts of clogging deadwood that clutters up human language.” “What about it?” said Fulham. “I applied it. Among other things, I applied it to this document here. I didn’t really need to for myself because I knew what it was all about, but I think I can explain it more easily to five physical scientists by symbols rather than by words.”
/…/
“The message from Anacreon was a simple problem, naturally, for the men who wrote it were men of action rather than men of words. It boils down easily and straightforwardly to the unqualified statement, when in symbols is what you see, and which in words, roughly translated, is, ‘You give us what we want in a week, or we take it by force.’”
/…/
“All right.” Hardin replaced the sheets. “Before you now you see a copy of the treaty between the Empire and Anacreon – a treaty, incidentally, which is signed on the Emperor’s behalf by the same Lord Dorwin who was here last week – and with it a symbolic analysis.” The treaty ran through five pages of fine print and the analysis was scrawled out in just under half a page. “As you see, gentlemen, something like ninety percent of the treaty boiled right out of the analysis as being meaningless, and what we end up with can be described in the following interesting manner: “Obligations of Anacreon to the Empire: None! “Powers of the Empire over Anacreon: None!”
“Foundation” by Isaac Asimov
There are a couple of noteworthy bits in the above passage besides the eye-catchers “symbolic logic” and “symbolic analysis”. First, potentially long documents are reduced to a handful of relevant symbolic statements. Such aggregation of semantic content might be achieved by ranking statements based on similarity to an external reference (with more similar statements ranking higher). Alternatively, one might use clustering of proposition to reveal groups of propositions with related semantic content. It might also be possible to identify chains of linked propositions (e.g. propositions that appear to describe a common entity).

Second, if we were to rank statements based on adherence to some semantic constraints (e.g. based on some similarity metric), we would like the semantic form of all sentences to be as regular as possible in order to facilitate comparison. More technically speaking, we would like the mapping from NL expressions to semantic form act as a normalization procedure. Third, the semantic form is interpretable in natural language suggesting that there exists a two-way mapping between natural language and semantic forms. In other words, the semantic form must retain compositionality so that we can derive the corresponding natural language expression from it. Sounds easy, right? 😅
Formalizing compositionality
Let us just kick off by proposing some notation. In order to represent relations between concepts with an emphasis on compositionality we could devise a special notation for expressing semantic relations between words (tokens in NLP lingo) in a sentence. Initially, we are not concerned about the modeling of meaning, but rather about the interaction patterns of different tokens.
For example, the semantic form of expression “a blue banana” might look like this:
mod(a, mod(blue, banana))
where mod(x, y) is a function that takes two arguments (a modifier term x followed by a term y that is modified by x). Accordingly, mod(blue, banana) is interpreted as “the meaning of the term blue modifies/specifies/constrains the meaning of the term banana”. Note that we are here not really concerned about the meaning of terms blue and banana, but rather in the asymmetry of the interaction between their meanings in the given expression (i.e. “blue” modifies the meaning of “banana”, but not vice versa).
In order to make the correspondence between sentence form and semantic form more familiar we could tag the words based on their grammatical role:
"a blue banana" --> mod(a:determiner, mod(blue:adjective, banana:noun))
In linguistics, it is common knowledge that adjectives modify nouns and that determiners modify nouns and noun phrases. In the example above, mod(blue, banana) corresponds to a noun phrase, which really is a semantically decorated instance of the term banana. As long as the behavior of noun phrases is virtually equivalent to that of nouns, there is no practical need to mark the noun phrase as a distinct semantic entity.
To add more expressive power, we might use functional notation with variables to rewrite the correspondence as follows:
| sentence form (with variables and values) |
semantic form (with variables) |
semantic form (with values) |
|---|---|---|
"a$a b$blue c$banana" |
mod(a, mod(b, c)) |
mod(a, mod(blue, banana)) |
where b$blue is interpreted as “assign the term blue to be the value of variable $b$” etc.
In mod(a, mod(b, c)) we have a semantic form with nested terms where the variable $b$ (e.g. adjective “blue”) modifies the variable $c$ (e.g. noun “banana”) and the variable $a$ modifies the term mod(b, c) (e.g. determiner “a” modifies the noun phrase “blue banana”). We could operationalise the semantic form mod(a, mod(blue, banana)) as “the term blue lends its semantic properties to the term banana and determiner a lends its semantic properties to the composite term “blue banana”.

A nice property of this notation is that one could operationalize it algorithmically (e.g. in neural networks). For example, the meaning of the expression “a blue banana” gets represented in the residual stream when we feed the expression mod(a, mod(blue, banana)) to the model. Attention heads compute the interaction result between specified terms in the appropriate order (e.g. the interaction between the embeddings of “blue” and “banana”) and write the result back to the residual stream. Next the embedding of “blue banana” in the residual stream is combined with the embedding of determiner “a” and the result is written back to the residual stream as the embedding corresponding to the form mod(a, mod(blue, banana)). The transformation $mod(x,y)$ might be represented by a suitable differentiable algorithm e.g. a projection of arguments $x$ and $y$ to a higher-dimensional space where these representations are multiplied and then projected back to the residual stream dimensions and added to the residual stream.
Alternatively, we could represent the expression mod(a, mod(blue, banana)) as a graph:
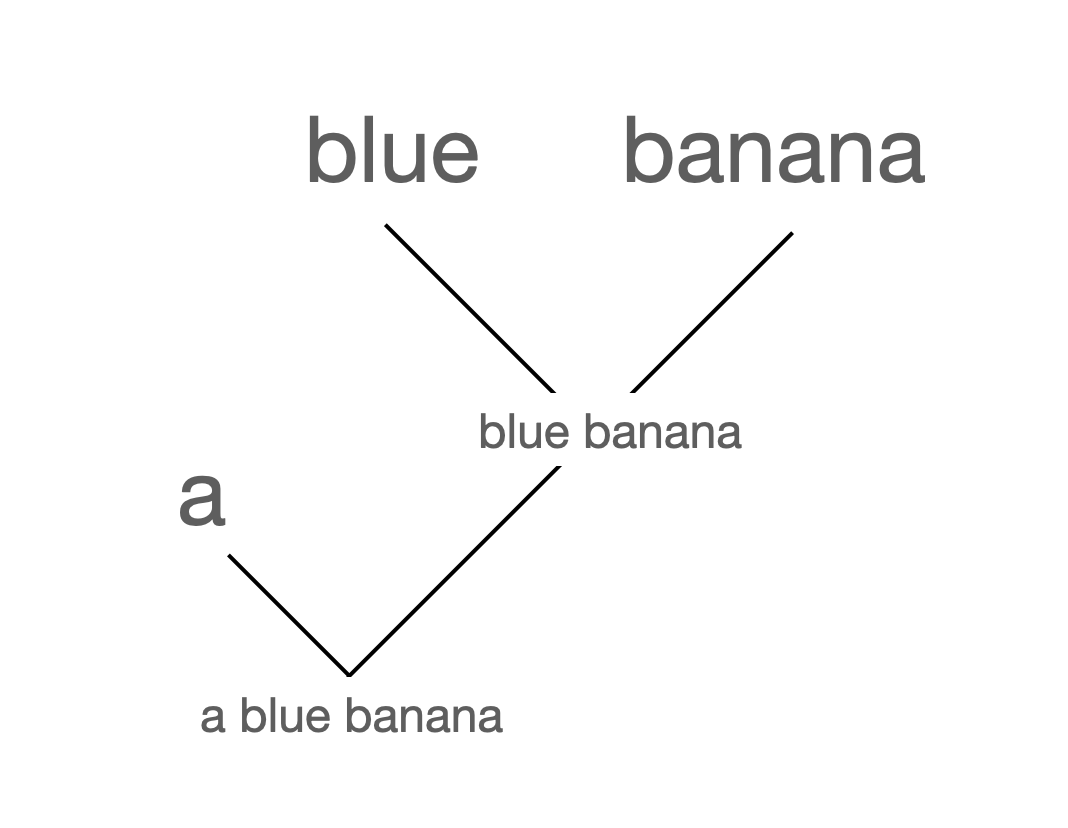
We could use the adjacency matrix $A$ of a graph neural network to specify what nodes need to interact with each other. A tricky issue with the graph above is that, initially, only the features of the leaf nodes (“a”, “blue”, “banana”) are given. Accordingly, the values of nodes “blue banana” and “a blue banana” are obtained by performing multiple rounds of multiplication between the feature matrix, node embeddings and the adjacency matrix to populate all nodes with corresponding embeddings. Ultimately, we are most interested in the embedding of the node “a blue banana” that forms the root of the tree.
Stress-testing the formalization
So far, we have been dealing with a simplistic linguistic expression and one might wonder whether it is at all feasible to obtain the semantic form of more complicated expressions such as sentences. Below are some examples to suggest that it is possible to derive a semantic form for a variety of sentence lengths. For clarity, I have tagged tokens with the corresponding parts of speech as some tokens are otherwise ambiguous (i.e. they can refer to different concepts depending on context).
Sentence form: “Pirenne is here.”
Semantic form:
Proposition(
Predicate(is:copula, here:pronoun),
Pirenne:proper_name
)
Sentence form: “It is a strange game.”
Semantic form:
Proposition(
Predicate(
is:copula,
XpA(
mod(strange:adjective, game:noun)
) #XpA
), # Predicate
it:pronoun # Subject
)
Sentence form: “I would not take it.”
Semantic form:
Proposition(
mod(
mod(not:adverb, would:auxiliary_verb),
take:verb
), # Predicate
I:pronoun, # Subject
it:pronoun # Object
)
Sentence form: “What are the penalties for non-compliance?”
Semantic form:
InterrogativeClause(
Proposition(
Predicate(
are:copula,
what:pronoun
), # Predicate
mod(
CaseAdpositionPhrase(
for:preposition,
non-compliance:noun
), # CaseAdpositionPhrase
XpThe(penalties:noun)
) # Subject
) # Proposition
) # InterrogativeClause
Sentence form: “There is a branch of human knowledge known as symbolic logic.”
Semantic form:
Proposition(
Predicate(
is:copula,
mod(
mod(
CaseAdpositionPhrase(
as:preposition,
mod(symbolic:adjective, logic:noun)
),
known:verb
),
mod(
CaseAdpositionPhrase(
of:preposition,
mod(human:adjective, knowledge:noun)
), # CaseAdpositionPhrase
XpA(branch:noun)
) # mod
) # mod
), # Predicate
there:pronoun # Subject
) # Proposition
Sentence form: “The phrase ‘all possible algorithms’ includes not just the algorithms known today, but any algorithm that might be discovered in the future.”
Semantic form:
Proposition(
mod(
just:adverb,
mod(not:adverb, includes:verb)
), # Predicate
mod(
Quoted(
mod(
all:adjective,
mod(possible:adjective, algorithms:noun)
) # mod
), # Quoted
XpThe(phrase:noun)
), # mod; Subject
ConnectivePhrase(
but:connective,
mod(
mod(today:adverb, known:verb),
XpThe(algorithms:noun)
),
mod(
Proposition(
mod(
CaseAdpositionPhrase(in:preposition, XpThe(future:noun)),
PassiveVoice(mod(might:auxiliary_verb, be:copula), discovered:verb)
), # Predicate
_, # Subject
that # Object
), # Proposition
mod(any:adjective, algorithm:noun)
) # mod
) # ConnectivePhrase; Object
) # Proposition
I am adding a few remarks aimed at the linguistically inclined reader. XpA and XpThe are used to mark the determiner phrase of indefinite and definite articles, respectively. In essence, the meaning of XpThe(x) would be equivalent to the meaning of mod(the, x). We will discuss this later why it might be useful to have more function primitives (e.g. CaseAdpositionPhrase, Proposition, XpA, XpThe, PassiveVoice etc) than just one (e.g. mod) . Xp is used instead of DP or NP in order to maintain a theory-neutral naming convention. CaseAdpositionPhrase is used as a language-agnostic label since, semantically, there is no difference whether a language uses adpositions or noun case to apply certain meaning.
Anyone still here? 😅

Key features of semantic forms
Those of you who have survived thus far will be treated with a couple of take-aways about the semantic forms presented above:
-
all of them represent a single term composed of a hierarchy of nested terms that have been associated by various relations. Relations are presented as functions taking one or more arguments. This single term forms the root of the parse tree and it represents a natural objective for the parsing process. In other words, whenever we are able to parse a natural language sentence into a semantic form that corresponds to a single term we can assume that our job is done. Note that it is an independent issue whether the result is correct or not.
-
Propositionappears to be a recurring relation type at the topmost levels. Thus, it looks like we might be able to convert most natural language sentences into propositions as long as they contain a relation (i.e. the predicate) and at least one entity (a subject or an object). This is convenient as most of written knowledge can be expressed in terms of propositions. It also suggests that the transformation into semantic form will be a potent normaliser for the weakly structured input.
Links to proof theory and reinforcement learning
Looking beyond the semantic forms, you might be able to spot the following:
-
Observation 1 does not guarantee the correctness of the parse tree. Accordingly, it would be nice to have a set of parsing rules that can tell us whether the parsing process was conducted according to the rules. For that we need two things:
1.1 break down the parsing process into individual steps where each step can be verified to be in agreement with a given set of transformation rules.
1.2 compile a set of transformation rules that act as guardrails to direct the parsing process. Ideally, we could use this set of transformation rules a) to ascertain whether any given parse tree is consistent with the rule set and b) to parse any valid sentence into the corresponding semantic form.
Now, 1.2 sounds a lot like proof theory where every parse tree is a theorem and the transformation rules are the axioms. The process of proving the correctness of the parse tree corresponds to the verification that the parse tree can be derived from the natural language form based on the transformations prescribed by the axioms. This is not the first time somebody suggests a proof theory for natural language semantics, but I would argue that the notation above deviates substantially from the notation of formal logic that tends to come across as somewhat brutal (e.g. see the parsing the string “the bad boy made that mess” here). As such, the notation presented above (although still rather ambiguous) makes it much more user-friendly and intuitive. In a following post, I will attempt to convince you that the interpretational ambiguity of the terms above can be reduced to a minimum by using a type system to encode certain elements of their conventional meaning.
-
In reinforcement learning lingo, we can call the process of parsing a single sentence an episode with the leaf terms of the parse tree as the initial state and the root term as the terminal state. Given a set of transformation rules as actions, we would learn an optimal policy to convert a natural language sentence into the corresponding semantic form. We might reward the agent every time the parsing process converges at a single term (the root) as long as we can be confident that the result is always correct. It is like navigating a maze where success corresponds to reaching the root term and dead ends correspond to expressions composed of multiple terms with no further applicable actions.
Breaking down the parsing process
Breaking down the parsing process into discrete actions is rather straight-forward. Using English language as an example, the parsing proceeds from left to right in a cyclic fashion:
-
the first cycle includes transformations that operate only on leaf terms
-
the second cycle includes transformations that operate on leaf terms and terms produced in the first cycle
-
the following cycles include transformations that operate on remaining leaf terms and terms produced in the preceding cycles
In order to make the parsing order deterministic, it is required that none of the terms that follow the arguments of current transformation exhibit a nesting depth higher than the maximum nesting depth of the arguments. You can find the nesting depth of a term easily by counting how many pairs of () brackets it contains. For example, given the expression
"reckless Alice and a mod(black, hole)"
we would get a parsing error when we attempted to parse “reckless Alice”
"a$reckless b$Alice [mod(a,b)] and a mod(black, whole)"
because both reckless and Alice exhibit nesting depth 0, but they are followed by a compound term mod(black, whole) with nesting depth 1.
Let us now proceed with parsing a whole sentence in deterministic order. For example, given the sentence "reckless:adjective Alice:proper_name jumps:verb into:preposition a:determiner very:adverb large:adjective black:adjective hole:noun", the parsing process would proceed as follows (you will need to scroll to the right in order to see the expressions in full):
# JSON object containing a parse tree with instructions for transformation
# '[]' are used to isolate the transformation from the rest of the expression
# a$<term>, b$<term> assign the following term as a value to the corresponding variable
[
# initial state
"reckless Alice jumps into a very large black hole",
# generic rule: a b --> mod(a,b)
# specific rule: "reckless Alice" --> "mod(reckless, Alice)"
"a$reckless b$Alice [mod(a,b)] jumps into a very large black hole",
# generic rule: a b --> mod(a,b)
# specific rule: "very large" --> "mod(very, large)"
"mod(reckless, Alice) jumps into a a$very b$large [mod(a,b)] black hole",
# generic rule: a b --> mod(a,b)
# specific rule: "black hole" --> "mod(black, hole)"
"mod(reckless, Alice) jumps into a mod(very, large) a$black b$hole [mod(a,b)]",
# generic: a b --> mod(a,b)
# specific: "mod(very, large) mod(black, hole)" --> "mod(mod(very, large), mod(black, hole))"
"mod(reckless, Alice) jumps into a a$mod(very, large) b$mod(black, hole) [mod(a,b)]",
# a b --> XpA(b)
"mod(reckless, Alice) jumps into a$a b$mod(mod(very, large), mod(black, hole)) [XpA(b)]",
# a b --> CaseAdpositionPhrase(a,b)
"mod(reckless, Alice) jumps a$into b$XpA(mod(mod(very, large), mod(black, hole)))
[CaseAdpositionPhrase(a,b)]",
# a b --> mod(b,a)
"mod(reckless, Alice) a$jumps b$CaseAdpositionPhrase(into, XpA(mod(mod(very, large), mod(black, hole)))) [mod(b,a)]",
# a b --> Proposition(b,a)
"a$mod(reckless, Alice) b$mod(CaseAdpositionPhrase(into, XpA(mod(mod(very, large), mod(black, hole)))), jumps) [Proposition(b,a)]",
# terminal state
"Proposition(
mod(CaseAdpositionPhrase(into, XpA(mod(mod(very, large), mod(black, hole)))), jumps),
mod(reckless, Alice)
)"
]
Summary
We started with the hypothesis that the analysis of semantic form based on the principle of compositionality will facilitate the algorithmic modelling of semantics. We proposed a notation for rendering natural language sentences into semantic form that is compositional and highly structured. We outlined a determinstic, stepwise process for parsing sentences into semantic form. We also suggested that the production and verification of semantic forms can be realised by the methods of proof theory and reinforcement learning.
In the next post, we will devise a way to algorithmically obtain the axioms for validation and execution of the parsing process. And yes – we will induce the axioms from the training set automagically without any hand-crafting of rules. For that purpose we will introduce a type system that will enable to derive parsing rules that generalize beyond individual tokens.
Additional notes
Below you can find some backround on the intended meaning of words “expression”, “statement”, “proposition”, “assertion” in the present context.
-
“expression” and “statement” refer to any syntactically correct sequence of one or more terms in the semantic form e.g.
beautiful flower,Proposition(ate, I, XpA(burger)),mod(charming, man),CaseAdpositionPhrase(in, place),Predicate(is, good). “Syntactically correct” certainly begs additional elaboration, but you can image that an expression likeCaseAdpositionPhrase(Predicate, good)will be invalid if we throw in some constraints around the types of arguments a function such asCaseAdpositionPhrasecan take. For example,CaseAdpositionPhraseaccepts a preposition as the first argument, butPredicateis not a preposition. A similar, but valid expression would be e.g.CaseAdpositionPhrase(for, good). -
Proposition is an expression that contains a predicate and a subject or an object. In the notation above, propositional relation is expressed by the form
Proposition(<predicate>, <subject>, <object>). Propositions are used to relate entities using predicates with entities acting as subjects and objects. Propositions are the elementary building-blocks of stories and theories. For example, they enable us to express causal relations between entities. -
Assertions are propositions made with the intent that they are true with respect to some reference frame (e.g. with respect to the physical or an imaginary world). Accordingly, they do not just represent relations between entities, but they intend to inform us that these relations are isomorphic with respect to an external reference frame. If they are indeed isomorphic, then the assertion evaluates to true otherwise it will evaluate to false. In the context of semantics form, we do not care whether a proposition is true or false. We are only interested in how the constituents of the proposition relate to each other (i.e. the internal consistency of the proposition) as opposed to external consistency (with respect to an external reference frame).