Deep semantics II

In the previous post Deep semantics I it was suggested that we might learn something new about language understanding by modelling semantic interactions between words in a sentence. We introduced a notation of semantic forms where sentences are transformed into nested expressions where interacting terms are embraced as arguments by functions that let us combine the meaning of these terms. For example mod(wicked, game) is an expression that instructs the interpreter to use the semantics of the adjective “wicked” to modify the semantics of the noun “game”. Since a wicked game is still a game, we can safely say that the term wicked has modified (or decorated) the term game so that the original meaning of game is preserved while additional attributes have been added to it. The compound term mod(wicked, game) is itself a term that can be used as an argument in another expression e.g. XpA(mod(wicked, game)) (corresponding to “a wicked game”). This process continues until we have combined all words in a sentence into one term (usually a proposition). For example, the semantic form of the sentence “That is a wicked game.” is represented by the following expression:
Proposition(
Predicate(
is,
XpA(
mod(
wicked,
game
)
)
), # Predicate
that # Subject
) # Proposition
# note! indentation is used to emphasize the multiple levels
# of meaning that get combined into a single term
The word “parsing” was used to denote the process of converting sentences into semantic form. At the very end of Part I, we promised to devise an algorithm for obtaining a set of rules for the validation of the parsing process. As long as we have humans composing semantic forms it would be nice to make sure that these forms follow a common set of transformation rules. Otherwise we might be able to convert a single sentence into whatever semantic form we happen to prefer and we would end up even more confused than at the outset.

In order to limit the number of ways a sentence can be parsed we will introduce a type system. Type system dictates the operations that can be performed on a term depending on its context. That will constrain the parsing process and ensure that all possible parsing paths will not be equally likely. Enforcing a type system requires us to assign types to all terms that might be found in a semantic form. In general, types can be more or less structured, but the simplest kind of type is a label. When we see two terms that share the same label we can infer that they are of the same type. To add more flexibility, we will allow a single term to possess multiple labels. The set of types associated with a single term is called the term’s type structure. We will also establish a type equivalence relation where term $A$ is considered to be of the same type as term B if the type structure of $A$ is a subset of the type structure of $B$.
So what labels should we use for types? Since we want to use the labels to direct the parsing process it seems most natural to label tokens based on their grammatical properties.
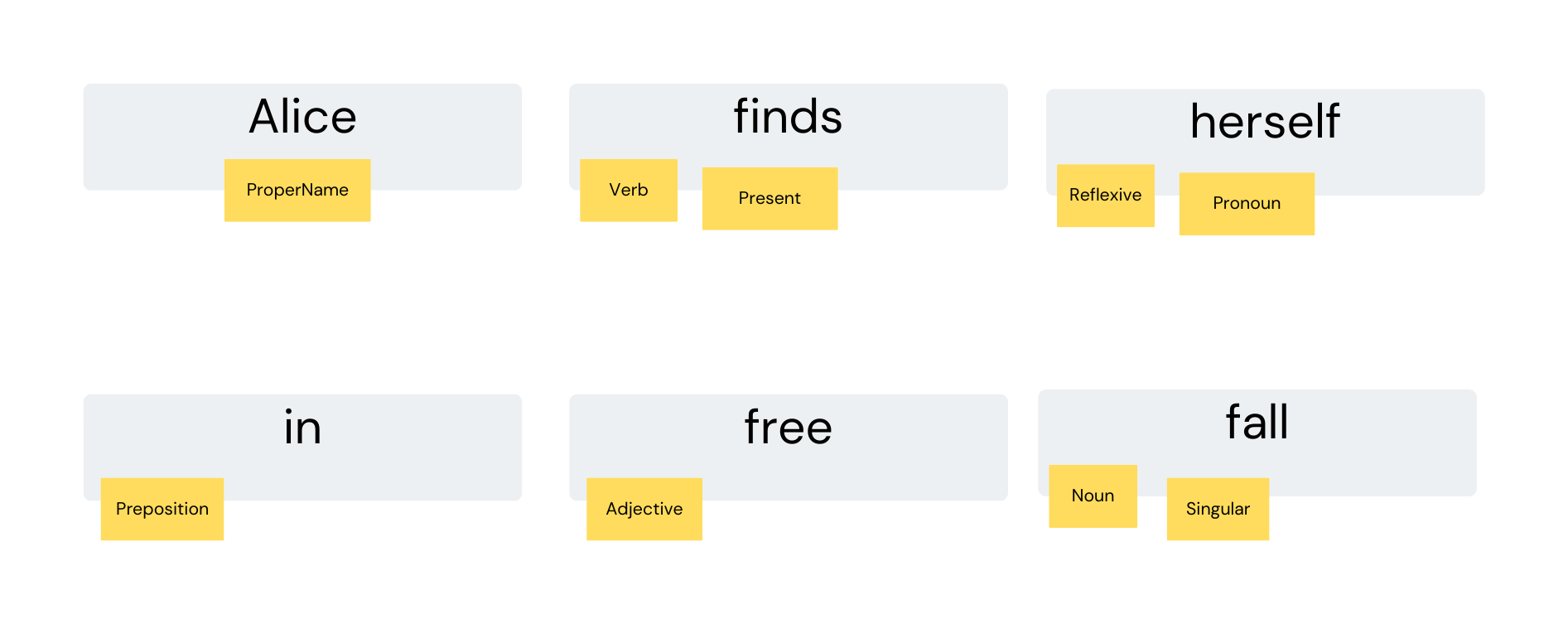
And what about tokens that change their grammatical properties depending on context? It is not uncommon for a single token to map to multiple terms with different type structure depending on the context. We solve this conundrum by assigning types to tokens based on their behavior in the sentence. For example, when a token that we are used to consider a verb behaves like an adjective (e.g. “it was a moving speech”), we will label it with the corresponding type in order to subject it to the same parsing rules that apply to adjectives.
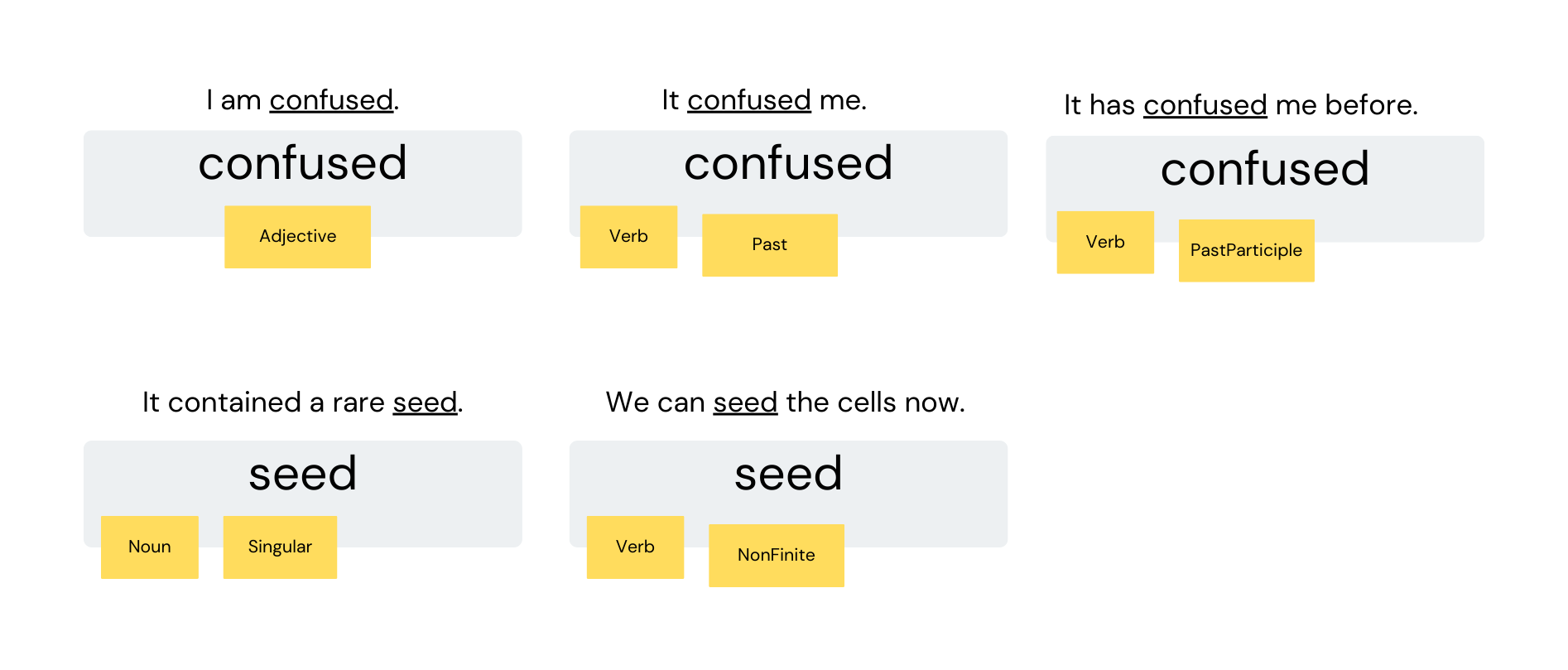
In order to map one token to one of multiple corresponding terms we can use a type selector:
tokens = {
# definition of type structure for terms
# corresponding to the token "seed"
"seed": {
"noun": ["Noun", "Singular"],
"verb": ["Verb", "NonFinite"]
},
# definition of type structure for terms
# corresponding to the token "confused"
"confused": {
"adjective": ["Adjective"],
"past": ["Verb", "Past"],
"past_participle": ["Verb", "PastParticiple"]
}
}
# get the term corresponding to noun "seed"
# "noun" is the type selector here
tokens["seed"]["noun"]
# get the term corresponding to the past participle
# form of verb "confused" (the tokens corresponding
# to past and past participle forms are often
# identical in English)
tokens["confused"]["past_participle"]

Let us suppose that we have mapped all tokens to corresponding type structures. Next, we need to make sure that the return values of functions have well-defined types in semantic forms. Here are some rather basic conventions:
-
mod(a:A, b:B):Binterpreted as:“the type of the term returned by expression
mod(a, b)is the type ofb” -
XpA(a):["XpA"],XpThe(a):["XpThe"],CaseAdpositionPhrase(a,b):["CaseAdpositionPhrase"]etc. meaning that the return type of the aforementioned functions is a type structure consisting of a single label that corresponds to the name of the function. Such functions are called type constructors, because all they really do is to bind the arguments into a new term with a type structure that contains the name of the constructor function. Since we use upper camel case for type labels (e.g. “PastParticiple”), we will also use it for type constructors.
It is important to understand that the above conventions are somewhat arbitrary. It is up to the designer of the type system to decide how many conventions to include and what exceptions (if any) are allowed.
Assuming that we have the type structure of all terms we care about, there remains one major challenge. We want to induce context-sensitive substitution rules that enable us to reproduce the parse tree solely based on the initial expression. It is here that the type system becomes really handy, because we can devise an algorithm that can construct a type-dependent matching pattern by recording type structures of arguments and terms surrounding the argument terms. These matching patterns can be used later to decide where it is appropriate to apply the associated transformation function. Henceforth, we will use the term substitution rule to refer to the pair consisting of a matching pattern and a transformation.
Let us see what substitution rules we might infer from the parsing tree of the sentence “reckless Alice jumps into a very large black hole” when instructed to include one position of context on either side of the arguments:
# each term has a corresponding type structure
# special term "_terminal" will be used
# to mark the beginning and end of sentence
vocabulary = {
"a": ["DeterminerA"],
"Alice": ["ProperName"],
"jumps": ["Verb", "Present"],
"black": ["Adjective"],
"into": ["Preposition"],
"hole": ["Noun", "Singular"],
"large": ["Adjective"],
"reckless": ["Adjective"],
"very": ["Adverb"],
"_terminal": ["Terminal"]
}
# Beginning of the parse tree
# --- Level 0 ---
level0 = "_terminal a$reckless b$Alice [mod(a,b)] jumps into a very large black hole _terminal"
rule0 = {
# type structures of arguments and one
# position of context on either side
"matching_pattern": (["Terminal"], ["Adjective"], ["ProperName"], ["Verb", "Present"]),
"transformation": "mod(a,b)",
# index is relative to the matching pattern, with
# the first position in the matching pattern
# corresponding to index 0
"variable_index": {"a": 1, "b": 2}
}
# --- Level 1 ---
# type structure of the new compound term
# "mod(reckless, Alice)" is ["ProperName"]
# due to convention 1
level1 = "_terminal mod(reckless, Alice) jumps into a a$very b$large [mod(a,b)] black hole _terminal"
rule1 = {
"matching_pattern": (["DeterminerA"], ["Adverb"], ["Adjective"], ["Adjective"]),
"transformation": "mod(a,b)",
"variable_index": {"a": 1, "b": 2}
}
# --- Level 2 ---
# type structure of the new compound term
# "mod(very, large)" is ["Adjective"]
# due to convention 1
level2 = "_terminal mod(reckless, Alice) jumps into a mod(very, large) a$black b$hole [mod(a,b)] _terminal"
rule2 = {
"matching_pattern": (["Adjective"], ["Adjective"], ["Noun", "Singular"], ["Terminal"]),
"transformation": "mod(a,b)",
"variable_index": {"a": 1, "b": 2}
}
# --- Level 3 ---
# type structure of the new compound term
# "mod(black, hole)" is ["Noun", "Singular"]
# due to convention 1
level3 = "_terminal mod(reckless, Alice) jumps into a a$mod(very, large) b$mod(black, hole) [mod(a,b)] _terminal"
rule3 = {
"matching_pattern": (["DeterminerA"], ["Adjective"], ["Noun", "Singular"], ["Terminal"]),
"transformation": "mod(a,b)",
"variable_index": {"a": 1, "b": 2}
}
# --- Level 4 ---
# type structure of the new compound term
# "mod(mod(very, large), mod(black, hole))" is ["Noun", "Singular"]
# due to convention 1
# when term is labeled as a variable in the
# expression, but it is not used as an argument
# in the transformation then it will be deleted.
# The following expression instructs among other
# things to delete the term "a".
level4 = "_terminal mod(reckless, Alice) jumps into a$a b$mod(mod(very, large), mod(black, hole)) [XpA(b)] _terminal"
rule4 = {
"matching_pattern": (["Preposition"], ["DeterminerA"], ["Noun", "Singular"], ["Terminal"]),
"transformation": "XpA(b)",
"variable_index": {"a": 1, "b": 2}
}
# --- Level 5 ---
# type structure of the new compound term
# "XpA(mod(mod(very, large), mod(black, hole)))" is ["XpA"]
# due to convention 2
level5 = "_terminal mod(reckless, Alice) jumps a$into b$XpA(mod(mod(very, large), mod(black, hole))) [CaseAdpositionPhrase(a,b)] _terminal"
rule5 = {
"matching_pattern": (["Verb", "Present"], ["Preposition"], ["XpA"], ["Terminal"]),
"transformation": "CaseAdpositionPhrase(a,b)",
"variable_index": {"a": 1, "b": 2}
}
# --- Level 6 ---
# type structure of the new compound term
# "CaseAdpositionPhrase(into, XpA(mod(mod(very, large), mod(black, hole))))" is ["CaseAdpositionPhrase"]
# due to convention 2
level6 = "_terminal mod(reckless, Alice) a$jumps b$CaseAdpositionPhrase(into, XpA(mod(mod(very, large), mod(black, hole)))) [mod(b,a)] _terminal"
rule6 = {
"matching_pattern": (["ProperName"], ["Verb", "Present"], ["CaseAdpositionPhrase"], ["Terminal"]),
"transformation": "mod(b,a)",
"variable_index": {"a": 1, "b": 2}
}
# --- Level 7 ---
# type structure of the new compound term
# "mod(CaseAdpositionPhrase(into, XpA(mod(mod(very, large), mod(black, hole)))), jumps)" is ["Verb", "Present"]
# due to convention 1
level7 = "a$_terminal b$mod(reckless, Alice) c$mod(CaseAdpositionPhrase(into, XpA(mod(mod(very, large), mod(black, hole)))), jumps) d$_terminal [Proposition(c,b)]"
rule7 = {
"matching_pattern": (["Terminal"], ["ProperName"], ["Verb", "Present"], ["Terminal"]),
"transformation": "Proposition(c,b)",
"variable_index": {"a": 0, "b": 1, "c": 2, "d": 3}
}
# --- Level 8 ---
# type structure of the new compound term
# "Proposition(mod(CaseAdpositionPhrase(into, XpA(mod(mod(very, large), mod(black, hole)))), jumps), Alice)" is ["Proposition"]
# due to convention 2
# this is the root term. further parsing is not possible.
level8 = "Proposition(mod(CaseAdpositionPhrase(into, XpA(mod(mod(very, large), mod(black, hole)))), jumps), mod(reckless, Alice))"
# End of the parse tree

Feeling confused? Apparently, you are not alone 😉.
In the example above, we presented a set of hand-crafted rules to reproduce the parsing tree of “reckless Alice jumps into a very large black hole”. It is fine to craft these rules by hand for a single parse tree, but it becomes infeasible with hundreds of parse trees. Also note, that the way the substitution rules above were constructed was rather rigid. First, the amount of context was fixed to one position around the arguments. But what if more context is needed to select the appropriate transformation in order to conform with other parse trees? Second, the matching pattern always included the complete type structure for each term. But what if a subset of the type structure is sufficient to select the correct transformation? It would be better if we had an algorithm that figured out the minimum amount of context for each substitution rule in order to be able to reproduce the parse tree without conflicting with other parse trees. In other words, from a set of possible matching patterns we would like to select the simplest one. Selecting the simplest explanation to your data is known as the principle of Occam’s razor.
The problem is that in any given situation there will be a large number of hypotheses that are consistent with the current set of observations. Thus, if the agent is going to predict which hypotheses are the most likely to be correct, it must resort to something other than just the observational information that it has. This is a frequently occurring problem in inductive inference for which the most common approach is to invoke the principle of Occam’s razor:
Given multiple hypotheses that are consistent with the data, the simplest should be preferred.
Universal Intelligence: A Definition of Machine Intelligence
Shane Legg, Marcus Hutter
But how can we rank matching patterns based on their complexity? It turns out that the type system makes this really easy. We just need to regard the complexity of each type to be inversely related to its frequency. And it makes sense too – types that are frequent in the corpus are more generic and, consequently, should be considered as more likely explanations than types that are rare. Since each type has a specific frequency in the corpus, we can devise an algorithm that builds the matching pattern in a stepwise manner by adding types to it. It starts from the argument terms and picks the most frequent type for each argument as the initial state. The algorithm then proceeds to add types in the increasing order of complexity until the pattern confirms with all parse trees in the corpus. It is also a good idea to assign a distance penalty to the type’s complexity depending on the distance of the associated term from the arguments. This will make the algorithm prefer shorter matching patterns to longer ones. Below is a description of the algorithm:
"""
** Find the simplest matching pattern that explains a set of parse trees **
1. initialize the matching pattern of argument terms to an empty set
2. select the simplest type from each argument's type structure
as the initial matching pattern
3. rank remaining types from the type structures of terms in the
expression based on increasing complexity. Apply a penalty to
the complexity of each type based on the distance of its bearer
term from the closest argument term. For example, types of
argument terms get zero penalty, types of terms adjacent to
the arguments get one unit of penalty and so on.
4. for each type in the ranked list
4.1. add the type to the matching pattern at the appropriate position
4.2. test whether the matching pattern breaks any parsing trees in the
corpus. IF yes, then go back to 4.1. IF not then return the matching pattern.
5. return error code if no matching pattern was found to satisfy all parse trees
"""
With this algorithm, we are guaranteed to find a matching pattern with lowest complexity that will be able to direct the parsing process selectively without interfering with other parse trees. When applied successfully to a set of parse trees, it will generate matching patterns for a set of substitution rules that collectively guarantee the internal consistency of (all parse trees in) the corpus. Equivalently, it generates a set of instructions that are sufficient to generate parse trees from the sentences included in the corpus.
Hopefully, you are about to experience a sense of accomplishment by now. In the previous post, we started out with little more than an excerpt from the Foundation and perhaps an excessive eagerness for the principle of compositionality. Meanwhile, by attaching a type system to symbols we have managed to derive an algorithm that induces parsing instructions from a set of parse trees. These parse trees correspond to well-structured semantic forms where interactions between the constituents of a sentence have been explicitly rendered. Provided enough computing power and time, we could use this algorithm to produce instructions for transforming any sentence to the corresponding semantic form. If only we had a comprehensive set of parse trees lying around that could be used to induce the parsing instructions … 🤔 (let me know if you know of any).
In the next post, we will compile a tiny corpus and observe automated rule induction in action.

Achilles: Oh… I should have seen it coming. All right. Now I see that in this way, structures like pucks are emerging again, only this time as COMPOSITE STRUCTURES made up out of many, many marbles. So now, my old question of who pushes whom around in the cranium - er, should I say “in the CAREENIUM”? - becomes one of SYMMBALLS versus MARBLES. Do the marbles push the symmballs around, or vice versa? And I can twiddle the speed control on the projector and watch the film fast or slow.
…
Tortoise: An excellent analogy. Symmballs are constantly forming and unforming, like blocks of ice melting down into chaotically bouncing water molecules - and then new ones can form, only to melt again. This kind of “phase transition” view of the activity is very apt. And it introduces yet a third time scale for the projector, one where it is running much faster and even the motions of the symmballs would start to blur. Symmballs have a dynamics, a way of forming, interacting, and splitting open and disintegrating, all their own. Symmballs can be seen as reflecting, internally to the careenium, the patterns of lights outside of it. They can store “images” of light patterns long after the light patterns are gone - thus the configurations of symmballs can be interpreted as MEMORY, KNOWLEDGE, and IDEAS.
WHO SHOVES WHOM AROUND INSIDE THE CAREENIUM?
DOUGLAS R. HOFSTADTER